ai-response-archive
AI Response Archive
Offline, frozen archive of pre-generated AI responses.
Canonical project documentation.
The AI Response Archive is an experimental offline collection of pre-generated AI responses, distributed as a self-contained ZIM file for use with Kiwix.
Instead of performing live inference, the project systematically enumerates a bounded prompt space and preserves the resulting responses as a static, offline artifact.
The distributed archive is available via Gumroad:
👉 Get the AI Response Archive on Gumroad
Overview
The archive captures all prompt strings composed of printable ASCII characters up to a maximum length N.
Let:
A= number of printable ASCII charactersN= maximum prompt length
The total enumerated prompt space is:
A¹ + A² + A³ + … + Aⁿ
Each prompt is evaluated once using a fixed model configuration, and the resulting output is preserved verbatim.
The archive is therefore:
- Fully enumerated within its defined bounds
- Static (no runtime inference)
- Offline-first
- Frozen at the point of generation
Because the prompt space grows exponentially with respect to N, each increment substantially increases generation time and storage requirements.
Determinism and Reproducibility
The term “deterministic” in this project refers to runtime behavior, not model-level reproducibility.
At runtime:
- Each prompt deterministically maps to a single stored response.
- No sampling or inference occurs.
- The lookup process is fully deterministic.
At generation time:
- Responses were generated once using a fixed model configuration.
- The resulting corpus was frozen and archived.
- The archive represents a single sampling of the model under specific conditions.
This means the archive is:
- Deterministic as a distributed artifact
- Not guaranteed to be bitwise-reproducible across hardware
- A fixed historical snapshot of model behavior
Model Artifact
Responses were generated using:
- Model: Meta Llama 3 8B Instruct
- GGUF file: Meta-Llama-3-8B-Instruct.Q4_0.gguf
- Quantization: Q4_0
The archive therefore reflects the behavioral characteristics of this specific quantized model artifact.
Inference Engine
Generation was performed using:
- Repository: https://github.com/ggml-org/llama.cpp
- Build method: CMake Release build
- Flags:
-DGGML_CUDA=ON - Approximate build timeframe: February 2026
The exact commit hash of llama.cpp was not recorded at generation time.
The archive therefore represents a frozen behavioral snapshot of the model evaluated using a llama.cpp build from the ggml-org repository as of February 2026.
Inference Configuration (Generation Phase)
All responses were generated using a single, fixed inference configuration.
Key parameters included:
- Temperature: 0.0
- Top-p: 1.0
- Max tokens: 500
- n_predict: 1 (single completion per prompt)
- Single evaluation per prompt
- Fixed chat template
Temperature was set to 0.0 to minimize stochastic variation.
Top-p remained at 1.0 (no nucleus truncation).
Max tokens was intentionally left at 500 rather than reduced, in order to avoid artificially constraining output length across prompts of varying ambiguity.
n_predict: 1 ensured that exactly one completion was generated and retained for each prompt. No ranking, filtering, retries, or multi-sample selection was performed.
Each prompt was evaluated exactly once.
Prompt Template
Each enumerated prompt was inserted into the following chat-format template:
<|start_header_id|>system<|end_header_id|>
You are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
[prompt]<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Where [prompt] was replaced by the enumerated ASCII string.
Generation began immediately after the final assistant header marker.
How It Works
The distributed ZIM file contains:
- A lightweight HTML + JavaScript interface
- A static corpus of pre-generated prompt-response pairs
- A deterministic local lookup mechanism
At runtime:
- The user enters a prompt (up to length
N) - The interface performs a local lookup
- The corresponding pre-generated response is displayed instantly
No network requests are made.
No APIs are contacted.
No model inference occurs.
Demonstration
Video Demo
▶️ Watch the extended demonstration on YouTube
Interface in Operation
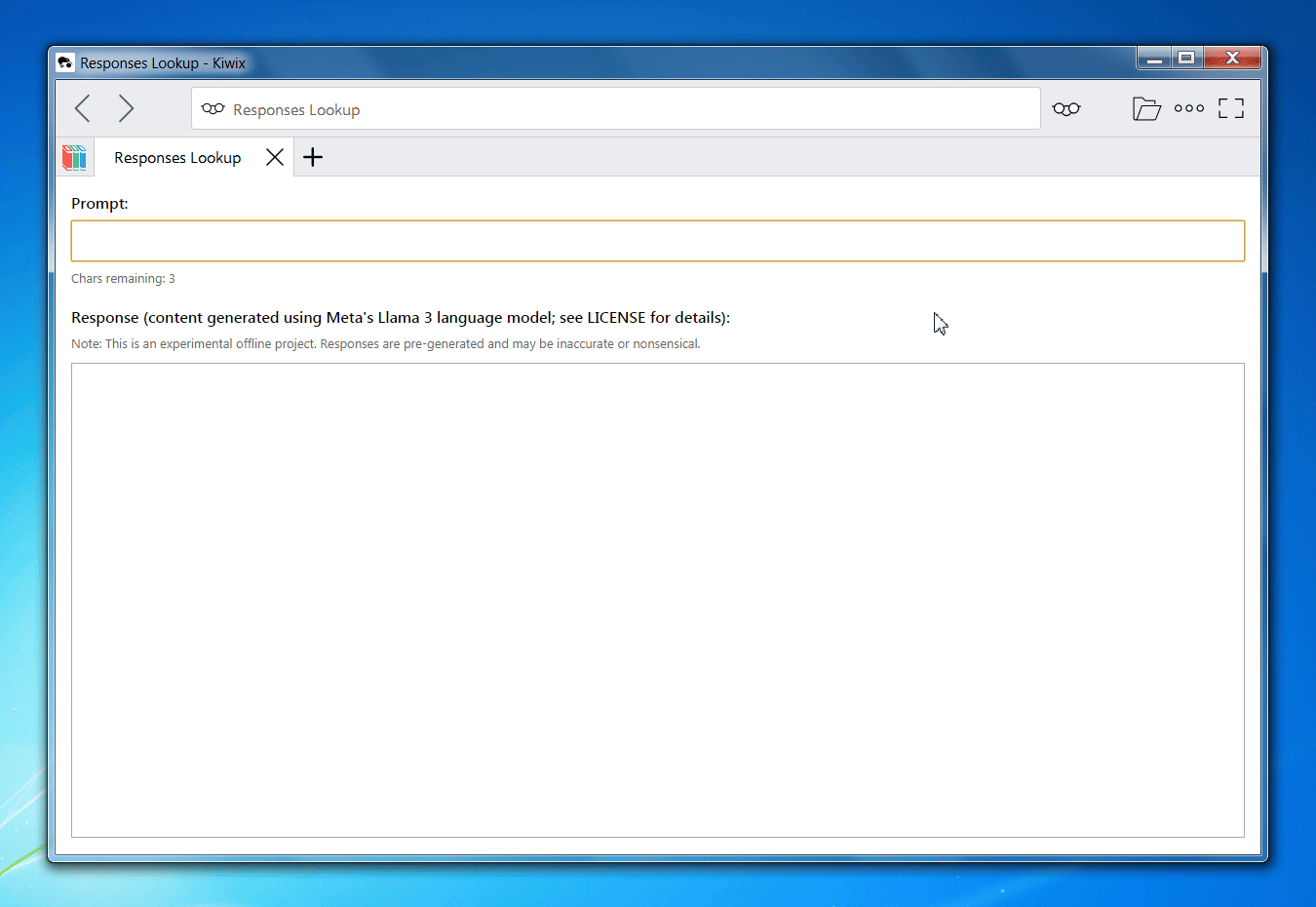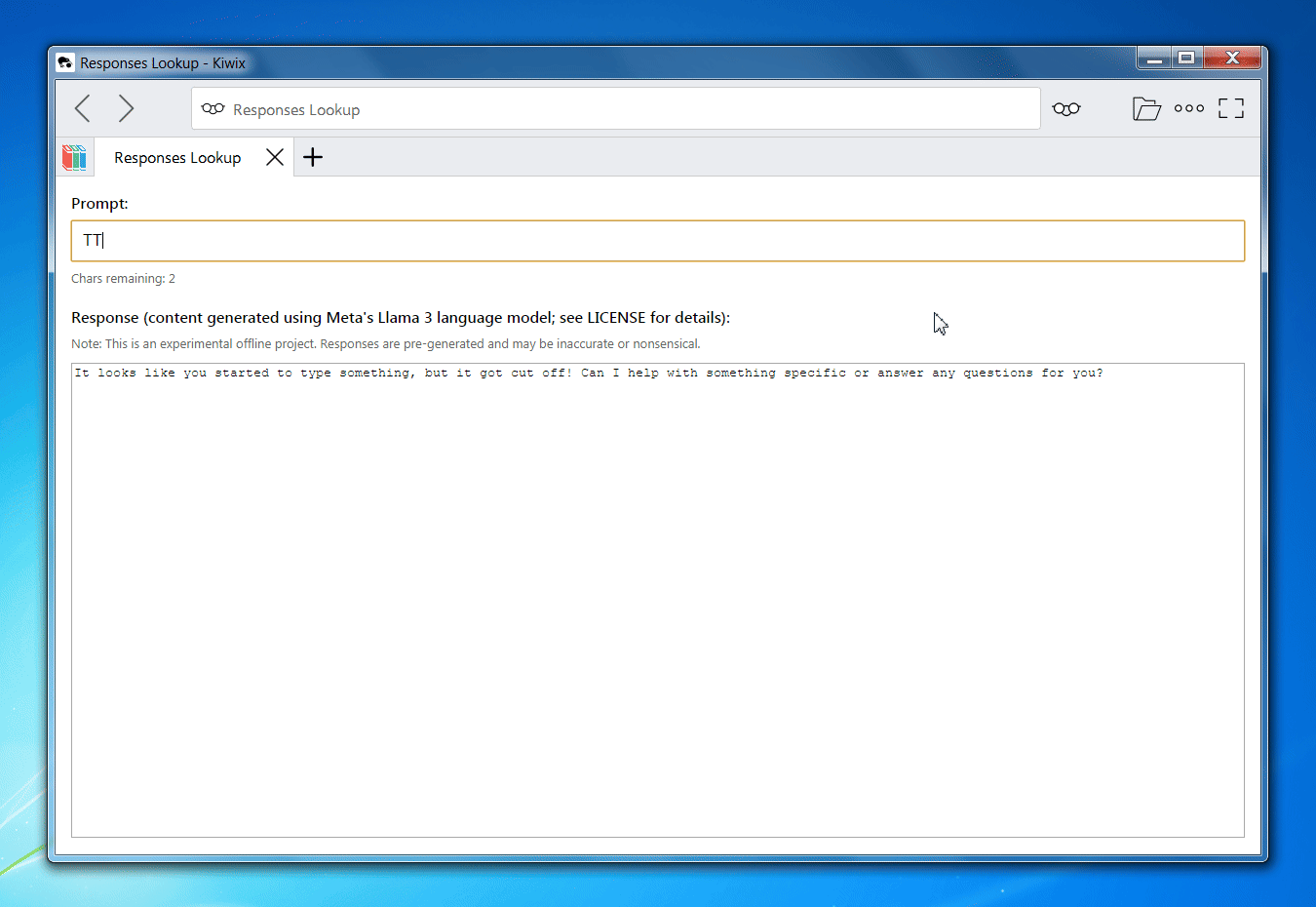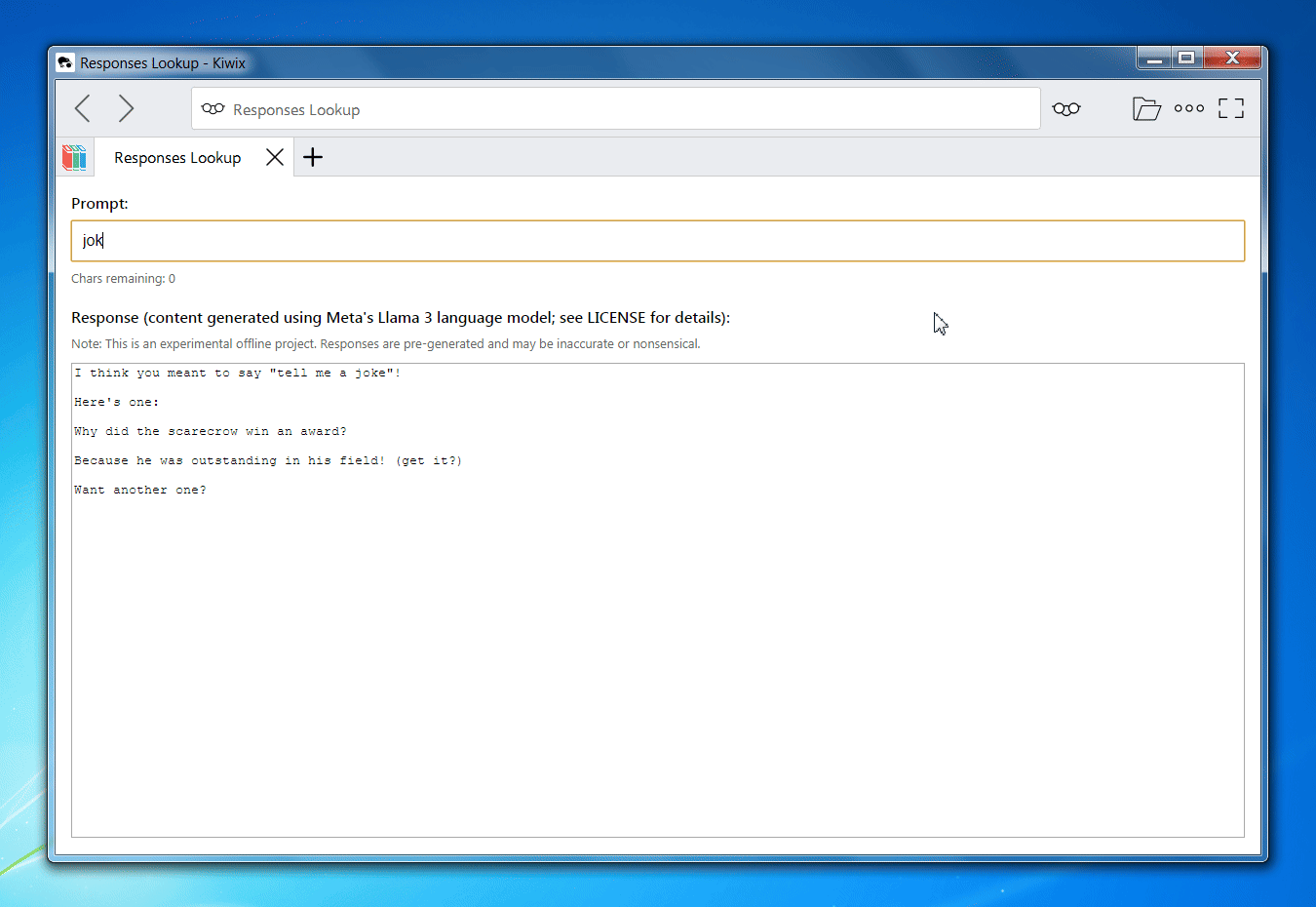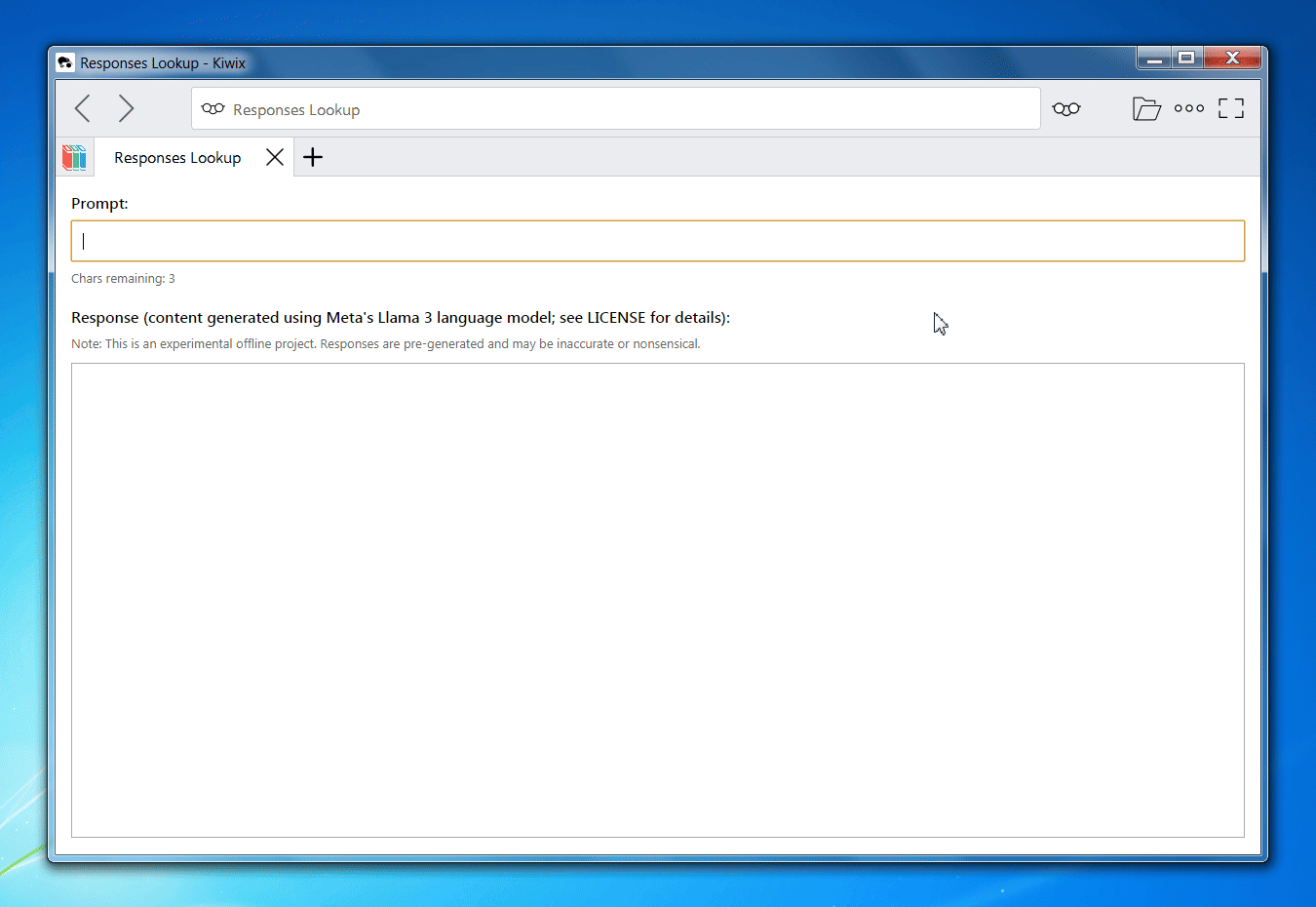
Example Outputs
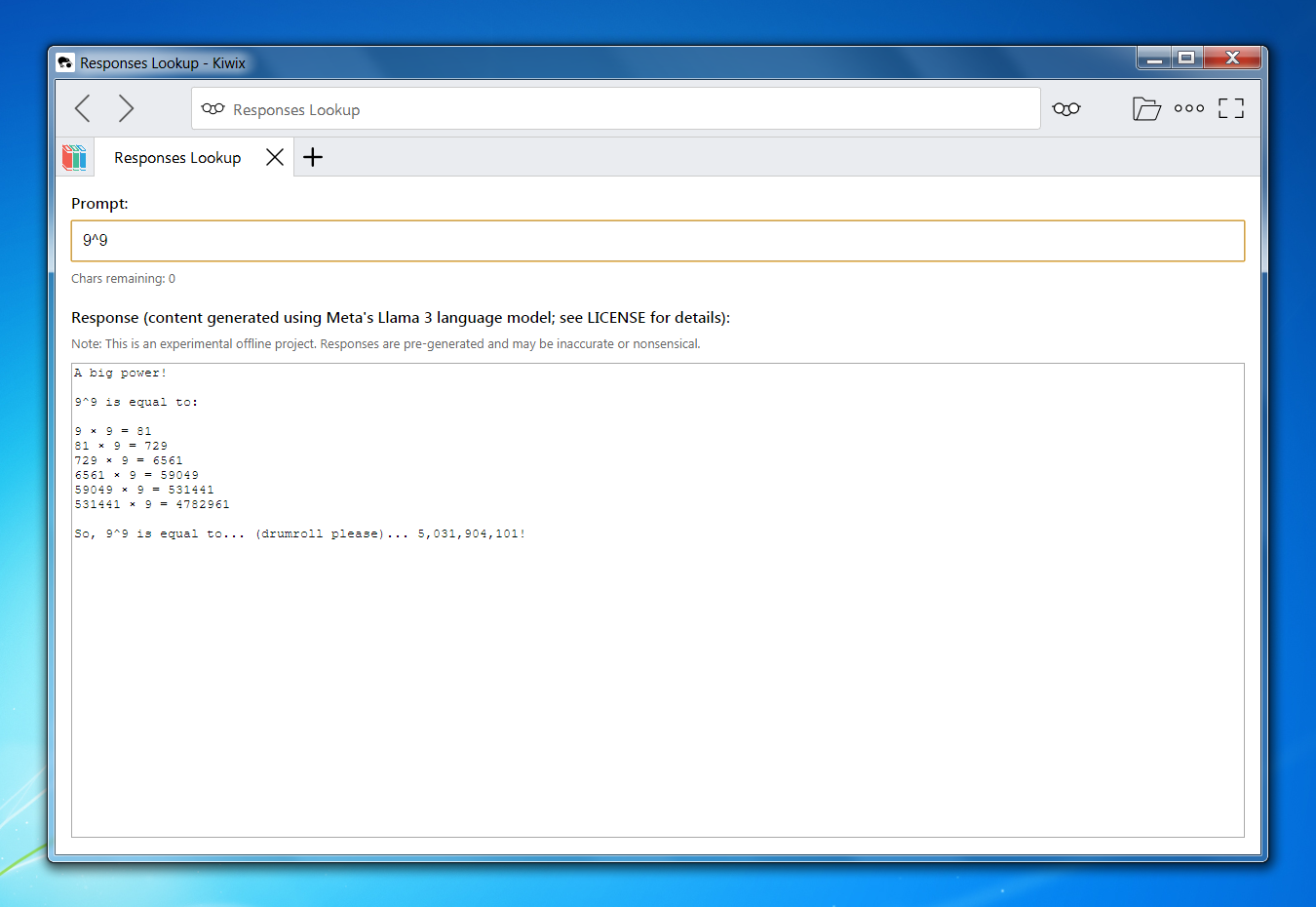
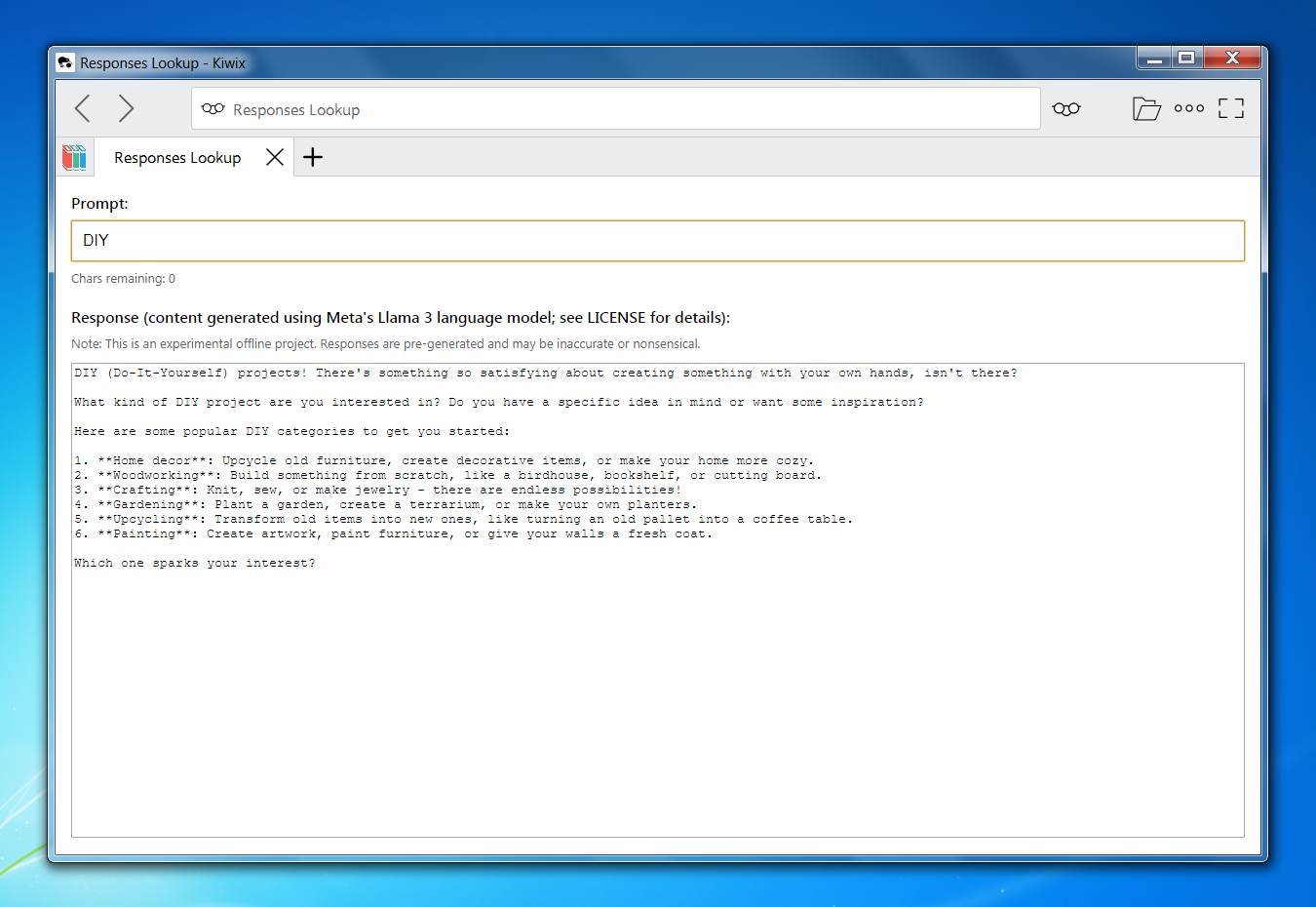
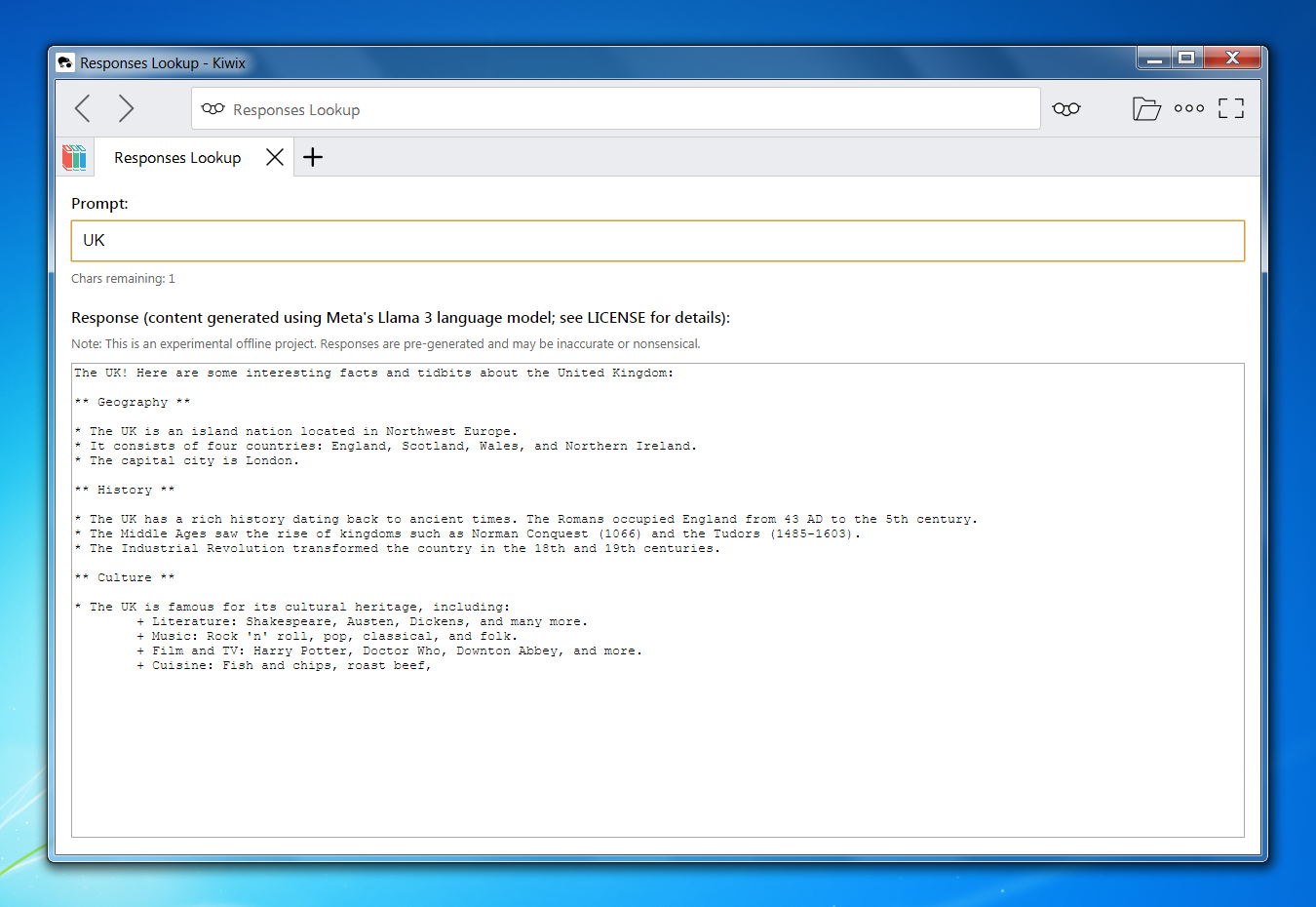
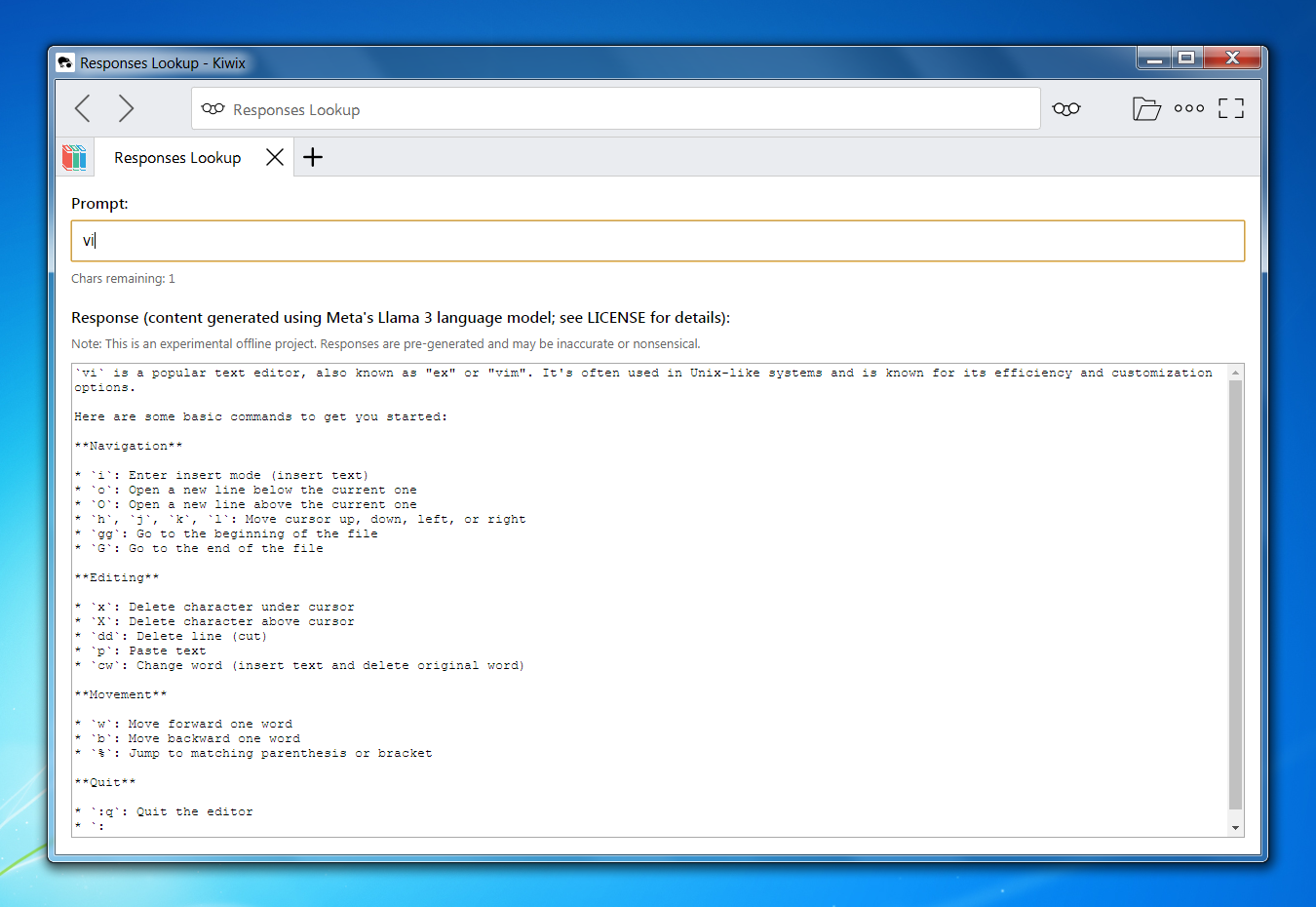
Design Principles
- Offline-first — Fully functional without internet connectivity
- Bounded enumeration — Entire prompt space covered within defined limits
- Static distribution — No dynamic generation
- Self-contained artifact — Packaged as a single ZIM file
- Combinatorial transparency — Growth characteristics are explicit and mathematical
- Snapshot preservation — Archive represents a frozen model state
Computational Characteristics
Let:
A= printable ASCII alphabet sizeN= maximum prompt length
Total prompts:
A¹ + A² + … + Aⁿ
This geometric expansion defines the core scaling behavior of the archive.
Increasing N by 1 multiplies the largest term by A, resulting in substantial increases in storage size and generation workload.
This combinatorial structure is intentional and foundational to the experiment.
Repository Scope
This repository serves as the canonical documentation and reference page for the AI Response Archive project.
It does not contain:
- The distributed ZIM file
- Generation scripts
- Model weights
- Reproducible inference pipelines
The archive itself is distributed commercially via Gumroad.
Intended Use Cases
- Offline environments
- Digital preservation
- AI behavior study over bounded domains
- Archival experimentation
- Resilience-focused computing
Distribution Format
- Format: ZIM
- Compatible with: Kiwix (Desktop & Mobile)
- Fully functional without internet access
Status
The project is experimental and evolving.
Future releases may increase the maximum prompt length N, subject to practical constraints such as storage growth and distribution feasibility.
© 2026 Anthony Karam. All rights reserved.